페이징 성능 개선
현재 토이프로젝트로 축구 커뮤니티 서비스를 개발하고 있습니다
https://github.com/kdmin0706/AmKorea
GitHub - kdmin0706/AmKorea: 축구 정보 커뮤니티
축구 정보 커뮤니티. Contribute to kdmin0706/AmKorea development by creating an account on GitHub.
github.com
게시글의 페이징을 구현하면서 문득, 대용량 데이터 를 가진 경우에는 기존 처리 방법과 똑같이 해도 되는지에 대해 궁금증이 생겨 테스트를 진행했다.
1. 기존 페이징 (offset)
기존 API 로직에 대해 살펴보겠습니다.
- Controller 로직으로 Pageable 객체와 검색하는 Title을 PathVariable로 받아서 postService를 호출합니다.

- postService 로직으로 검색 조건의 title이 있는 경우를 모두 찾아 페이징 처리 후 dto로 반환합니다.
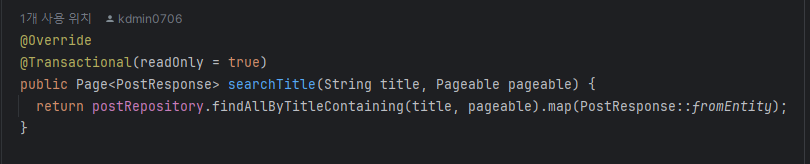
- PostRepository 에서는 JPA를 이용해서 NamedQuery를 활용한 상태입니다.

기존 로직의 문제점
- 기존 로직을 활용하면, Spring Data JPA 를 통해서 Pageable 객체를 손쉽게 활용할 수 있다.
- 데이터가 적은 상태라면 성능적인 이슈도 느끼지 못한다.
- 데이터가 증가함에 따라서 쿼리 속도가 굉장히 느려지고, DB 커넥션 지속시간이 길어짐에 따라 성능적인 부하를 견딜 수 없게 됩니다.
그럼 이 기존 로직인(Offset 기반 페이징)에 대해 알아보겠습니다.
- Pageable 구현체인 PageRequest의 필드인 page는 Offset(page * size)으로 작동하게 됩니다.
- Offset은 MySQL 기준으로 쿼리 조건에 해당되는 데이터의 몇 번째 row부터 반환하는 것입니다.
- 몇번째 row인지 확인하기 위해서는 해당 offset(row) 이전의 데이터까지 모두 조회해야한다.
- 즉, 쉽게 말하면 앞에서 읽었던 행을 다시 읽어야한다.
- 그래서 요청되는 page(page number)가 작을 수록 속도가 빠르지만, page가 커지면 size는 같지만 조회해야할 데이터가 많아지기 때문에 속도가 느려질 수 밖에 없다.
실제 쿼리로 확인하기
- Dummy Data를 이용해서 체크해보겠습니다
- 테스트를 위해서 해당 게시글(Post)를 약 500만건으로 진행해보겠습니다.

기존에 사용하던 페이징 쿼리는 일반적으로 이 형태이다.
SELECT *
FROM post p
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지 번호
LIMIT 페이지 사이즈
해당 쿼리를 예시를 삼아 약 500만개의 데이터를 가지고 테스트하면 execution time 약 3초가 넘게 걸린다.

2. JOIN 을 이용한 페이징(커버링 인덱스)
- 커버링 인덱스란, 쿼리를 충족시키는데 필요한 모든 데이터를 인덱스에서만 추출 할 수 있는 인덱스를 의미한다.
- 보통 SELECT 절까지 포함하는 경우 너무 많은 칼럼을 인덱스로 포함시켜야하므로 조인을 통해 사용한다.
SELECT *
FROM post p
JOIN (
SELECT id
FROM post
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지번호
LIMIT 페이지사이즈
) as temp
ON temp.id = m.id
테스트 진행 시에, 이전 offset 방식에 비해 3s에서 800ms로 줄은 것을 확인할 수 있다.
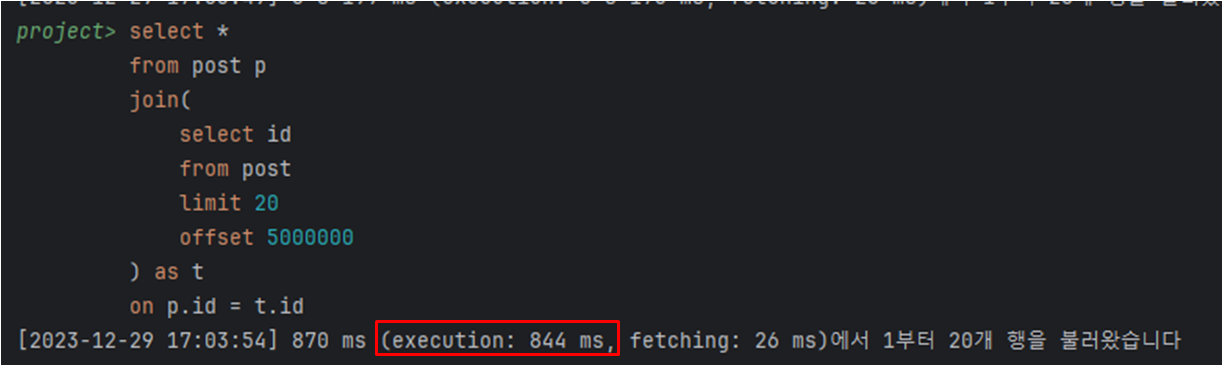
그럼 왜 커버링 인덱스가 빠르게 처리가 가능할까?
일반적으로 인덱슬르 이용해 조회되는 쿼리에서는 가장 큰 성능 저하를 일으키는 부분은 인덱스를 검색하고 대상이 되는 row의 나머지 칼럼값을 읽기 위해 데이터 블록에 접근하는 시간 때문이다.
페이징 쿼리의 상황에서는 offest, offset ~ limit 등을 수행할 때도 데이터 블록으로 접근을 하게 되는데
커버링 인덱스 방식을 이용하면 where, order by, offset ~ limit 과 같은 검색을 데이터 블록 접근 없이 인덱스 검색으로 빠르게 처리하고, 걸러진 row에 대해서만 데이터 블록에 접근하기 때문에 성능의 이점을 얻게 된다.
3. Paging 개선하기 (No Offset)
기존 페이징 방식에서 No Offset으로 구조를 변경하는 방법으로
기존 페이징 방식은 번호(offset), 페이지 사이즈(limit) 을 기반으로 한다면
NoOffset은 페이지 번호(offset)이 없는 더보기(More) 방식을 사용한다.
NoOffset 방식은 조회 시작 부분을 인덱스로 빠르게 찾아 매번 첫 페이지만 읽도록 하는 방식이다
(보통 클러스터 인덱스인 PK 를 이용하여 조회 시작 부분을 찾는다)
SELECT *
FROM post
WHERE 조건문
AND id < 조회 마지막 id
ORDER BY id DESC
LIMIT 페이지 사이즈
위의 쿼리와 같이 직전 조회 결과의 마지막 id를 기억하거나 입력 받아서 매번 이전 페이지 전체를 건너뛸 수 있다.
즉, 아무리 페이지를 뒤로 가더라도 처음 페이지를 읽은 것과 동일한 성능을 가지게 되어 문제를 해결할 수 있다.
이해하기 쉽게 정리해보면 형태입니다.
SELECT * FROM user WHERE id > 마지막조회ID LIMIT 페이지사이즈;
SELECT * FROM user WHERE id > 20 LIMIT 20; # 21~40 출력
SELECT * FROM user WHERE id > 40 LIMIT 20; # 41~60 출력
...
SELECT * FROM user WHERE id > 999980 LIMIT 20; # 999981~100000 출력
테스트 진행 시에, 이전 offset 방식에 비해 3s에서 12ms로 엄청 많이 줄은 것을 확인할 수 있다.

해당 쿼리를 이용해서 로직을 수정해보겠습니다.
그 전에 Controller 로직 수정을 한 내용입니다.
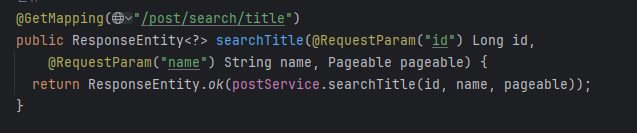
기존 로직과는 다르게 id를 받아옵니다.
id는 pageNumber( ) 이고, name은 찾고 싶은 제목의 이름을 받아옵니다.
ex) GET http://localhost:8080/api/post/search/title?id=31&name=제목
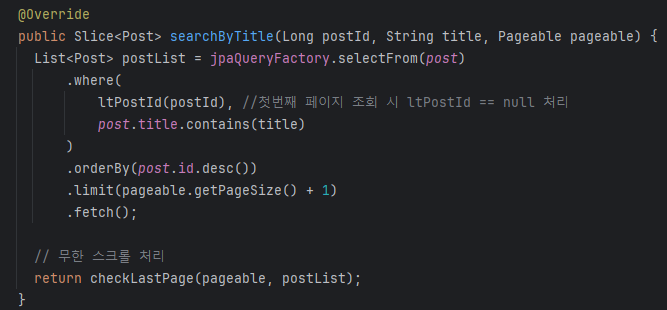
Spring Data JPA 가 아닌 QueryDsl 을 이용해서 수정해보겠습니다.
QueryDsl 을 사용하는 이유는 Java 로 쿼리를 진행 시킬 수 있기 때문에 Runtime 이전에 오류를 잡아낼 수 있다.
또한, 조건문을 이용해서 null 에 관한 예외 처리도 가능합니다.
No-Offset 방식을 사용할 때는 다음과 같은 조건이 생깁니다.
1. 정렬된 인덱스 값이 필요하다.
2. 인덱스 key 값에 중복이 있으면 안된다(데이터가 누락될 수 있음)
3. 페이징 버튼(1,2,3)을 사용하는 경우 어렵다.
정렬되고 중복이 되지 않은 인덱스 값을 가지는 즉, 무한 스크롤 방식에 사용이 가능하기에 Slice 를 사용합니다.
Slice는 Page와 다르게, 페이지 번호를 매길 필요가 없기 때문에 전체 데이터 건수가 필요하지 않습니다.
단지 다음 페이지의 존재 여부만 필요할 뿐입니다. 다음 페이지가 존재한다면 [더보기] 버튼을 활성화하거나 스크롤을 내렸을 때 다음 데이터를 불러와야하기 때문입니다.
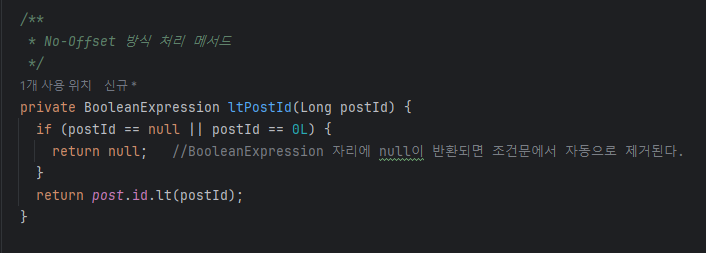
findAllByTitleContaining 함수를 QueryDsl로 변경한 함수입니다.
해당 메서드에서 No-Offset을 적용한 부분은 ltPostId( ) 입니다.
No Offset 으로 처음 조회하면 몇 번째 id 부터 조회하는지 알 수가 없기 때문에 null 값을 넘겨줘야한다.
where 절에서 null을 반환하면, Order by는 DESC로 설정했다는 가정하여 내림차순으로 페이지 사이즈 만큼 조회된다.
클라이언트 측에서는 반환된 데이터 중 마지막 데이터 id 를 기준으로 '마지막 조회 id' 를 알아낸 뒤, 이후 요청에 포함해서 서버에 전송해주면 된다.

Slice가 무한 스크롤 방식에 최적화 된 이유 중 하나가 SlicmImpl을 생성할 때, 애초에 파라미터로 다음 페이지가 있는지 여부를 넣어줄 수 있기 때문이라고 생각된다.
우리는 클라이언트에게서 요청으로 들어온 pageable 객체의 pageSize에 +1을 해서 limit을 걸었다.
만약 지금 페이지가 마지막 페이지가 아니라면 요청으로 들어온 pageable의 pageSize보다 results의 size가 더 클 것이다. 하지만 만약 현재 페이지가 마지막이라면 +1해서 조회했더라도 result의 size가 더 크지는 않을 것이다.
실제로 반환할때는 result에 확인용으로 추가한 데이터를 remove해준 뒤, 최종적으로 SliceImpl을 반환하면 된다.
한 줄 마무리
직접 테스트를 진행한 덕분에 각 방식의 동작하는 과정과 성능적으로 얼마나 차이가 나는지에 대해 알 수 있었습니다.
page는 게시판과 같이 총 데이터 갯수가 필요한 환경에서 어울리는 것 같고,
slice는 모바일과 같이 총 데이터 갯수가 필요없는 환경(무한스크롤 등) 에서 어울리는 것 같다.
서비스의 특성에 따라 사용할 방식을 정하고, 추후 성능을 개선하는 방향으로 가는 것이 올바르게 개발하는 것 같습니다.
Reference
https://jojoldu.tistory.com/528?category=637935
https://velog.io/@pood/no-offset-%ED%8E%98%EC%9D%B4%EC%A7%80%EB%84%A4%EC%9D%B4%EC%85%98
https://velog.io/@ddongh1122/MySQL-%ED%8E%98%EC%9D%B4%EC%A7%95-%EC%84%B1%EB%8A%A5-%EA%B0%9C%EC%84%A0
https://velog.io/@cmsskkk/No-Offset-Paging-ngrinder2
'Spring > Issue' 카테고리의 다른 글
| Java 8 LocalDateTime Serialization, Deserialization 이슈 (0) | 2024.01.01 |
|---|---|
| @NotBlank, @Valid 적용하는 방법 (0) | 2023.11.16 |
| [오류 처리] Failed to load ApplicationContext (0) | 2023.11.09 |

댓글